We are collecting data from an extremely heterogeneous primary source, the English Port Books series (TNA E190). This series is made up of thousands of volumes written in different handwriting styles, in Latin and English, by many port officials over hundreds of years.
Using high-quality digital images, we created bespoke handwritten text recognition models and data structurisation techniques to parse the millions of words contained into an actionable dataset.
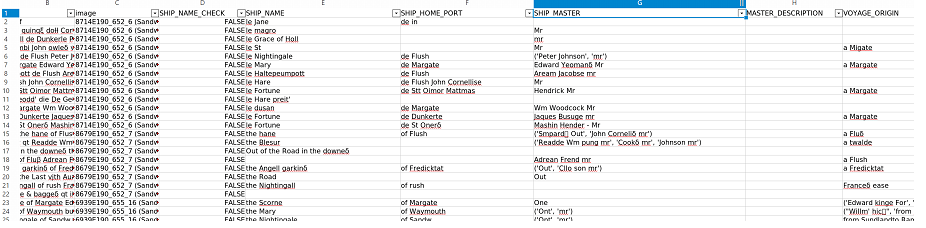
A sample of this data is shown below:
Obtaining high-definition photographs of these records is difficult. Text blurring lowers the accuracy of any transcribing system powered by artificial intelligence. Most people could benefit from upgraded equipment and simple tweaks to camera settings. We provide free advice and can provide affordable and effective onsite archival photography services.
Southampton University used our camera kit to photograph the entire Port Books archive at the National Archives in Kew, London. Around 60,000 high-definition images were taken using this setup.
The images below provide examples of our work to obtain high-resolution images from the archive:


